你以为是 Nginx 配错了、证书失效了,或者某个 Docker 容器挂了。
但这次我遇到的真实根因,是一个更隐蔽、也更值得长期记住的问题:回包走偏了。
很多人在家里做外网发布时,都会逐步把环境搭到一个“看起来很成熟”的状态:
- 有自己的域名
- 有 HTTPS
- 有反向代理
- 有 Docker 宿主机
- 有主路由端口转发
- 还有旁路由、透明代理或者分流策略
单独看,每一层都不算复杂;但一旦这些组件叠在一起,故障就很容易跨层出现。最麻烦的是:表象出现在应用层,根因却可能藏在网络层。
这次故障,就是一个非常典型的例子。
一、故障表面:像 SSL 问题,也像 Nginx 问题
最开始看到的现象,其实非常迷惑人:
- 外网通过域名访问家庭服务时,HTTPS 异常
- 内网访问基本正常
- Docker 容器都还在运行
- Nginx 也正常监听
- 域名解析和证书表面上看不出明显错误
如果你也遇到这种情况,第一反应大概率会和我一样,先怀疑这些方向:
- 是不是 Nginx 配错了?
- 是不是证书有问题?
- 是不是某个 upstream 不可达?
- 是不是 Docker 网络出了问题?
这些方向都合理,也都应该查。
但这次的问题在于:你把这些地方都查一遍,可能还是找不到真正的根因。
因为出问题的地方,根本不在这些“最显眼”的层。
二、真实架构:入口在主路由,默认出口却在旁路由
为了避免暴露真实环境,我把这次的链路抽象成最核心的结构:
外网域名
↓
主路由(把公网高位端口转发到内网 443)
↓
Docker 宿主机上的统一 Nginx 反向代理
↓
不同容器服务乍看这条链路没有问题。
真正的关键在于另一个条件:
Docker 宿主机默认出站路径:宿主机 → 旁路由 → 主路由 → 外网
也就是说:
- 请求是从主路由进来的
- 但响应默认却想从旁路由出去
这就形成了一个非常典型、但又很容易被忽略的风险:
入口和出口不是同一条逻辑路径。
而这,正是后面所有异常的源头。
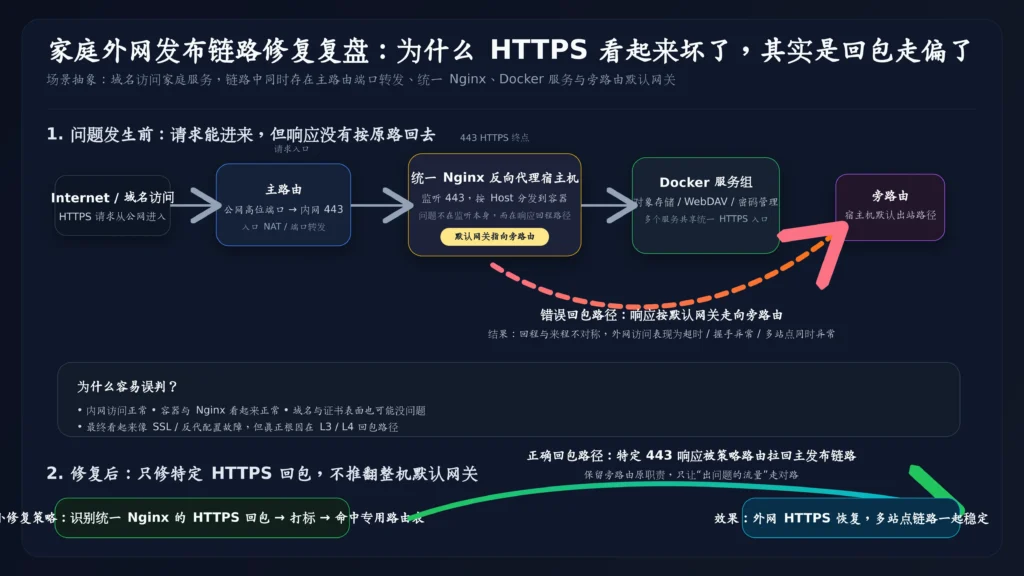
三、真正根因:不是证书坏了,而是回包走偏了
把这次问题讲透,其实一句话就够:
外部请求是经主路由端口转发进入宿主机的,但宿主机响应时按照自己的默认网关,把回包发给了旁路由,导致回程路径和来程路径不一致。
这就是典型的不对称路由。
在家庭网络这种带 NAT、端口转发和状态跟踪的环境里,不对称路由很容易导致:
- 会话状态不一致
- NAT 回程不符合预期
- HTTPS 握手异常、超时或访问不稳定
- 多个站点同时表现得像“应用层坏了”
换句话说:
SSL 反代只是出问题时最先被看到的地方,但不是问题真正发生的层。
这也是为什么它特别容易误导人。
四、为什么这种问题特别容易被误判
这类故障最难的地方,不是修,而是识别。
因为它同时满足三个很容易把人带偏的条件。
1. 应用层看起来没坏
容器正常、Nginx 正常、配置也未必有问题,所以人会本能地继续在 7 层打转。
2. 内网访问通常是好的
这会让人误以为:既然服务本身健康,那一定只是外网证书或反代的问题。
3. 多个服务一起异常
这说明它不是单个业务的问题,而更像是“统一入口层”或“统一返回路径”出了问题。
也就是说,当多个服务共用一个 HTTPS 发布入口时,排障视角就不能只盯单个站点。
如果这时还只在 server_name、upstream 或容器端口里兜圈子,就很容易浪费大量时间。
五、最关键的认知转折:从“站点配置问题”切换到“链路问题”
这次排障中,真正有价值的转折,不是某一条具体命令,而是判断框架的变化:
- 一开始,把它当成“某个站点配置错误”
- 后来,把它当成“统一发布链路的返回路径错误”
一旦从第二个角度去看,很多零散现象会立刻串起来:
- 为什么多个站点一起异常
- 为什么容器本身看起来没问题
- 为什么内网访问却正常
- 为什么改单个站点配置没有根治
很多网络故障真正难的地方,不是不会改配置,而是你能不能及时意识到:
问题不一定出在你正在看的那一层。
六、最终修复:不推翻现有网络,只修“出问题的那部分流量”
这次我最后采用的修法,不是大改拓扑,也不是把宿主机所有流量都改回主路由。
而是一个更稳、更可解释的思路:最小影响面修复。
核心逻辑是:
- 保留宿主机现有默认网关设计
- 不去推翻旁路由既有职责
- 只识别统一反代服务产生的 HTTPS 回包
- 只让这部分流量按正确路径返回
抽象后,大概是这样:
如果数据包属于统一反代服务的 HTTPS 回包
→ 打上策略标记
→ 命中专用路由表
→ 从主路由回外网
其他普通流量
→ 继续走宿主机默认网关
这个修法的价值在于,它不是“碰巧修好”,而是同时满足了四件事:
1. 影响面小
不动整机全部流量,只修真正出问题的那一部分。
2. 逻辑清晰
问题在哪一层,规则就修哪一层,因果关系很清楚。
3. 保留原有架构意图
旁路由该做的代理、分流和默认出站仍然照常工作。
4. 适合长期维护
以后再遇到类似问题,你知道该检查哪里,而不是从头再猜一遍。
七、为什么我不建议一上来就“全盘回退”
在家庭网络这类已经有一定复杂度的环境里,最危险的排障方式往往不是“不动”,而是一次改太多。
比如:
- 直接把默认网关全改掉
- 同时改主路由、旁路由、Nginx、Docker 网络
- 把所有“看起来可疑”的配置一口气清理掉
这样做也许能把问题“碰巧修好”,但你会失去一个更重要的东西:可复用的因果理解。
你很难回答:
- 真正根因到底是什么?
- 哪条改动是必须的?
- 哪条改动只是误打误撞?
- 下次再遇到,还能不能稳定复现和修复?
这也是我后来越来越重视“最小影响面修复”的原因。
它不仅是在修问题,也是在保留问题的可解释性。
八、这次故障最值得带走的 4 个经验
1)外网 HTTPS 异常,不一定是证书或反代坏了
如果只有外网异常,而内网和应用层都正常,要尽早检查回包路径。
2)多个站点一起出问题时,先怀疑共用入口层
这通常比优先盯单个容器更有效。
3)端口转发只解释“怎么进来”,默认网关决定“怎么回去”
很多人理解了入口 NAT,却忽略了响应包最终还是由宿主机自己的路由表决定出口。
4)家庭网络同样值得使用“最小影响面修复”思路
不是所有问题都要靠推翻架构解决。很多时候,一条精确的策略路由,比整体回退更稳。
九、如果你也遇到类似问题,可以按这个顺序排查
如果你也在家里维护域名、反代、Docker 和旁路由的组合环境,建议按这个顺序检查:
第一步:先确认应用层是否健康
- 容器是否正常运行
- Nginx 是否正常监听
- upstream 是否可达
第二步:确认入口层是否成立
- 域名解析是否正常
- 主路由端口转发是否正确
- HTTPS 与证书是否基础可用
第三步:如果仍然只有外网异常,就检查路径层
重点看:
- 宿主机默认网关是谁
- 入口主路由是谁
- 回包是否可能经过旁路由
- 是否已有策略路由、mark 或自定义路由表
第四步:优先修“故障流量”,不要先动“全部流量”
这通常是降低风险、保留现有架构稳定性的关键。
十、结语
这次修复给我最大的提醒是:
当家庭外网发布同时叠加了主路由端口转发、统一 Nginx、Docker 宿主机、旁路由和代理策略时,很多问题就不再只是“站点部署问题”,而是一个跨越 L3 / L4 / L7 的链路问题。
你看到的可能是 SSL 报错,真正出问题的却可能是回包路径。
如果要把这次复盘浓缩成一句最值得记住的话,那就是:
当外网域名访问家庭服务出现 HTTPS 异常时,别只查证书和反代,也一定要查“响应包是怎么回去的”。